
 AI+安全
AI+安全 数据安全
数据安全 数据基础设施
数据基础设施 态势感知
态势感知 云安全
云安全 基础安全
基础安全 终端安全
终端安全 商用密码
商用密码 软件供应链安全
软件供应链安全 网络空间靶场
网络空间靶场 工业互联网安全
工业互联网安全 物联网安全
物联网安全






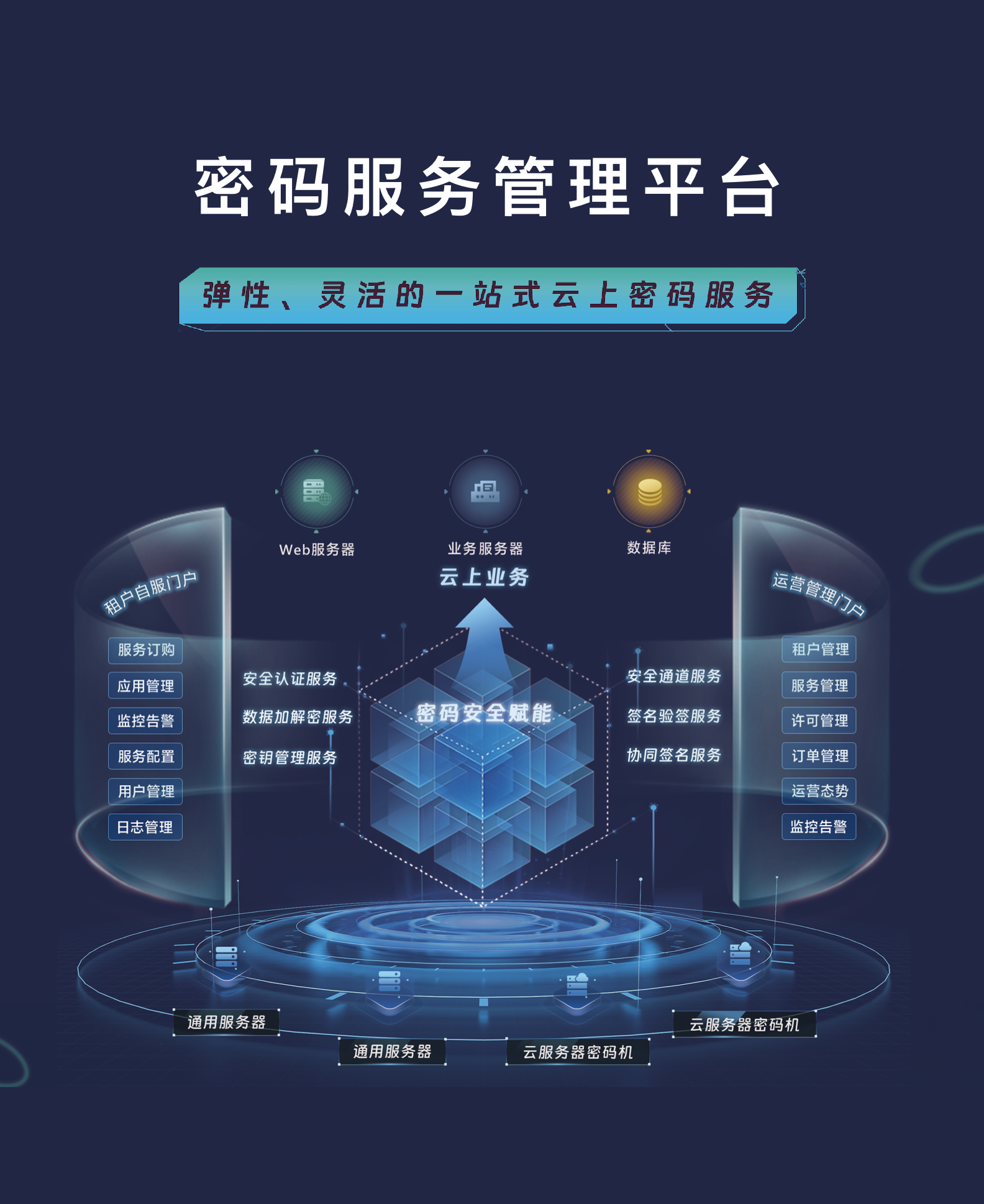



 安全托管服务
安全托管服务 运营管理服务
运营管理服务







【安恒观察】开年王炸“Sora”:炸在哪里?有何风险?

安恒观察
有政策解读,有技术探讨,有行业理解。
我们不仅关注“现在”,更着眼“未来”;
不仅传递观点,更倡导实践;
不仅瞄准机遇,更描绘前行路径;
不仅关注风险,更关心解决之策。
引领方向,服务市场
携手筑牢安全屏障,为客户保驾护航!
信息量大、细节生动、场景逼真、镜头切换流畅自然......
近日,OpenAI发布了首个文生视频模型Sora,可以用文字指令生成长达1分钟的高清视频。Sora重新定义了AI文生视频在现阶段的技术极限,给2024年开年后的AI生成世界扔了个“王炸”,在全社会引发热议,媒体关注不断。
在OpenAI官方出具的技术报告中,对Sora的定位为“作为世界模拟器的视频生成模型”。近日,2024新奥门资料CTO刘博,安恒研究院院长、高级副总裁王欣等多位技术专家接受媒体采访,针对Sora是什么?国内的Sora什么时候出现?大模型的实现技术逻辑是什么?可能的安全风险在哪里?等多个问题进行了详细解答与回复,系统阐述了Sora以及大模型技术带来的里程碑式改变。

一、Sora是什么?炸在哪里?
简单来说,Sora可以理解为具备视频生成、视频合成、图片生成三大核心功能的世界模拟器。
它能够理解用户的文字提示,直接生成长达一分钟不同尺寸的视频,且这一分钟的视频并非单一场景,而是由多个镜头组成。且能够确保多个镜头之间的人物、场景等整体3D效果与细节的一致性,并实现不同主题和场景组成的视频之间的无缝过渡。
它的强项在于:
一、精准理解
它能依据背后复杂的逻辑体系,仅通过文字精准分析出你想要视频是什么样子。
二、贴近现实
它生成的图或视频包含复杂的多角度镜头和富有情感的多角色,但都很合理,也很贴合实际生活。比如视频中看到的下雪、反光等复杂自然系统中的场景,符合现实逻辑。
三、细节真实
生成视频背景细致入微,动物的毛发都非常清晰,可以真正把你想表达东西具像化呈现,甚至比你想要的还更真实更炫酷。
二、技术上的难点在哪里?
主要的技术突破点在于生成式基础——通用人工智能(AGI),采用游戏、无人驾驶和机器人领域验证的世界模型,构建出的文生视频模型,达到模拟世界的能力。它可以模拟生成图片、一首诗或一首歌。但是,视频远比图片、文字要复杂。究其原因,视频的逻辑性、连贯性、对细节的关注度非常看重。
文生视频,需要依托大模型,对海量现有图片和视频数据进行训练。只有充分了解背后的逻辑,才能生成更合理的逻辑。以GPT为例,它要生成一首七言绝句,就必须得见过足够多的七言绝句样本。
文生视频的难度在于,视频本身数据量大且非常复杂。大语言模型如果要捕捉到视频数据的逻辑,会面临巨大的挑战。但是,Sora可以做到。它不仅能捕捉到视频中的细节信息,也能涵盖宏观场景化信息,进而生成非常合理、看上去都找不到破绽的视频。
三、从生成图到生成视频,
其背后最大的突破就在哪?
一方面是对数据量的考验。一张1000×1000像素的图片可以将图片内容表达得较为清晰。但是视频的转换逻辑不同。每一秒钟都要处理几十帧或者上百帧高清图片,才能保证视频的逻辑性和连贯性。以海洋生物骑自行车为例,要想显得合理,动物要长脚,还要穿鞋。类似这样逻辑性、连贯性很强的视频,要比图片复杂100倍甚至1000倍。这种复杂度背后便是对模型算力的要求。
另一方面,Sora使用了Transformer架构,建立在DALL·E 3和GPT模型之上。尤其是要生成长达1分钟的有运动、多机位的视频,需要穿梭表达这些信息,至少是10倍或者100倍复杂度的提升。
四、大模型可以实现文生视频的
底层逻辑是什么?
无论是视频、图片还是语言,都是基于多种技术进行编码,进而转化成矢量矩阵,最终用数字来呈现。
我们可以称其为跨媒体的转换,例如语音转换视频、视频转换文字等。所以它的底层编码过程是屏蔽不同媒体介质差别的过程,最终将其变成统一的表达方式。
不管通过什么样的方式,都可以通过transformer技术计算相似度、逻辑性。因此,无论是语言,还是文字、图片、音频还是视频,对于大模型来讲,底层表达逻辑区别并不大,区别主要在于计算的复杂度,以及如何构造你的编码和transformer技术,从而更好地表达所承载的介质及其关系。
其底层模型,均为通用的大语言模型。即对于自然语言,甚至于计算技术承载的数字化介质来说,都可以通过统一的数字矩阵方式进行表达,抹掉差别,用统一的模型支撑不同的任务。
首先通过编码,将文字变成数字化矩阵,然后依托该矩阵,从海量视频数据中抓取匹配场景,再自动化生成。视频也是同理,需要通过编码一帧帧生成。
值得一提的是,Sora在视频内容的合理性层面实现重大突破。例如,以前的AI视频经常会产生1个人有6个手指或某根手指突然间比其他手指要粗一点。因为某些大模型很难捕捉到如此细节的画面,导致会出现“常识性错误”。但Sora在很多细节上的处理不错。它的实现主要是human feedback,即通过人的反馈,再持续增强学习。
五、面对新技术,需要去注意什么?
面对一个未成熟的新技术,我们已经看到它巨大的可能性和潜力。
首先,我们要拥抱它,大量使用它,研究原理,从而助力我们自身技术和产业的升级。
第二,随着AI生成内容的真实性越来越高,如何区分真实视频和AI生成视频,以及如何确保内容的真实性和透明度,将成为社会需要共同面对的挑战。
举个例子,随着文生视频、文生文、文生图操作的便捷化,自然而然就会产生造假等问题,比如未来虚假消息、虚假视频、虚假图片的真伪鉴别。比如诈骗文案、钓鱼诈骗的鉴别,比如未来会不会利用虚假视频、虚假消息等进行舆论战。
六、当前阶段,面对AI的高速发展,
作为企业有什么样的呼吁?
第一,从当前来看,国内要大力发展自主可控的芯片,同时希望政府给予更多的算力支持。国家在政策、人才、基础设施方面,对AI产业的投入还是比较大。全国各地在建立AI计算中心,以比较低廉的价格供应给相关企业使用,让我们都可以以较低的成本来使用AI的算力,国家针对AI算力的科研经费及产业的专项支撑,提供了较大的支持,对AI类型想拥抱AI企业来讲,都是一个很好机遇。
第二,国家的监管机构,需要进行全方位的有效监管。例如利用技术手段识别哪些视频的真实性。可以采取在人工生成视频上打水印、加特殊标签等方式,确保视频可以追溯,从而保护个人隐私,保护个人合法权利。
七、Sora的发布及近期大模型技术变革,
会如何影响技术发展的进程?
与前三次工业革命类似,每一次工业革命并不是一个应用上的突破,而是基础能力上的突破,这会导致生产力提升,生产成本大幅下降。AI大模型技术有可能会成为第四次工业革命的重要驱动。
我们看到,Sora在媒体领域具备很大潜力。当然,它并非横空出世或一枝独秀。我们更应该将其看成一个重要的里程碑。罗马不是一天建成的,类似研究机构和企业,其实都在逐步推进相关技术和产品的进步。我们每个人都可以抓住这样的机遇,参与到伟大变革中。
八、2024新奥门资料会如何应对大模型变革
所伴随的机遇和挑战?
第一,从自身出发,很多员工已经开始将AI作为工作助理,例如写代码、报告、PPT等,大幅提升工作效率。
第二,我们充分认识到大模型技术对网络安全技术的推动力。
当前,我们在做的数据安全、威胁检测等,都可以通过大模型技术提升精准度和可理解性。客户在使用我们的产品时,能够大大降低使用成本,同时让我们的产品变得可控。可以说,大模型技术能够帮助我们的产品实现大的跨越。
并且,我们已经推出了网络安全垂直领域的大模型——恒脑,来解决更多的问题。这是我们的一个探索,未来该技术也会不断地拓展其边界,应用到更多领域。
九、当前阶段,浙江乃至中国要做出
极具影响力的大模型,
我们重点应该在哪些方面发力?
1、加快算力基础设施建设。
大模型技术的发展基于海量的数据和再加海量的算力。所有信息需要通过大模型技术捕捉,对于算力的要求非常高。因此,要充分调动资源,加快建设相关的算力基础设施。
2、加快AI人才培养。
技术发展过程并非一帆风顺。当前,我们对于大模型、算法有精准了解的人才还是比较稀缺。针对于模型训练全生命周期可以做到全对全、端对端的全流程调优的人才,也非常欠缺。因此,要加快在该领域人才的培养和引进。
展望未来

经过前期发展,我国在AI领域积累了大量人才。国外顶级研究团队中不乏华人身影。所以我们具备很好的人才基础。
通过算力技术的进步,相信我们能在不久的将来就会迎头赶上世界顶尖水平。在以AI大大模型为驱动的第四次工业革命中,中国完全有机会走在世界前列,成为最主要的“头部玩家”。
让我们拥抱AI,乘风而起,扶摇直上。
往期精彩回顾










