
 AI+安全
AI+安全 数据安全
数据安全 数据基础设施
数据基础设施 态势感知
态势感知 云安全
云安全 基础安全
基础安全 终端安全
终端安全 商用密码
商用密码 软件供应链安全
软件供应链安全 网络空间靶场
网络空间靶场 工业互联网安全
工业互联网安全 物联网安全
物联网安全






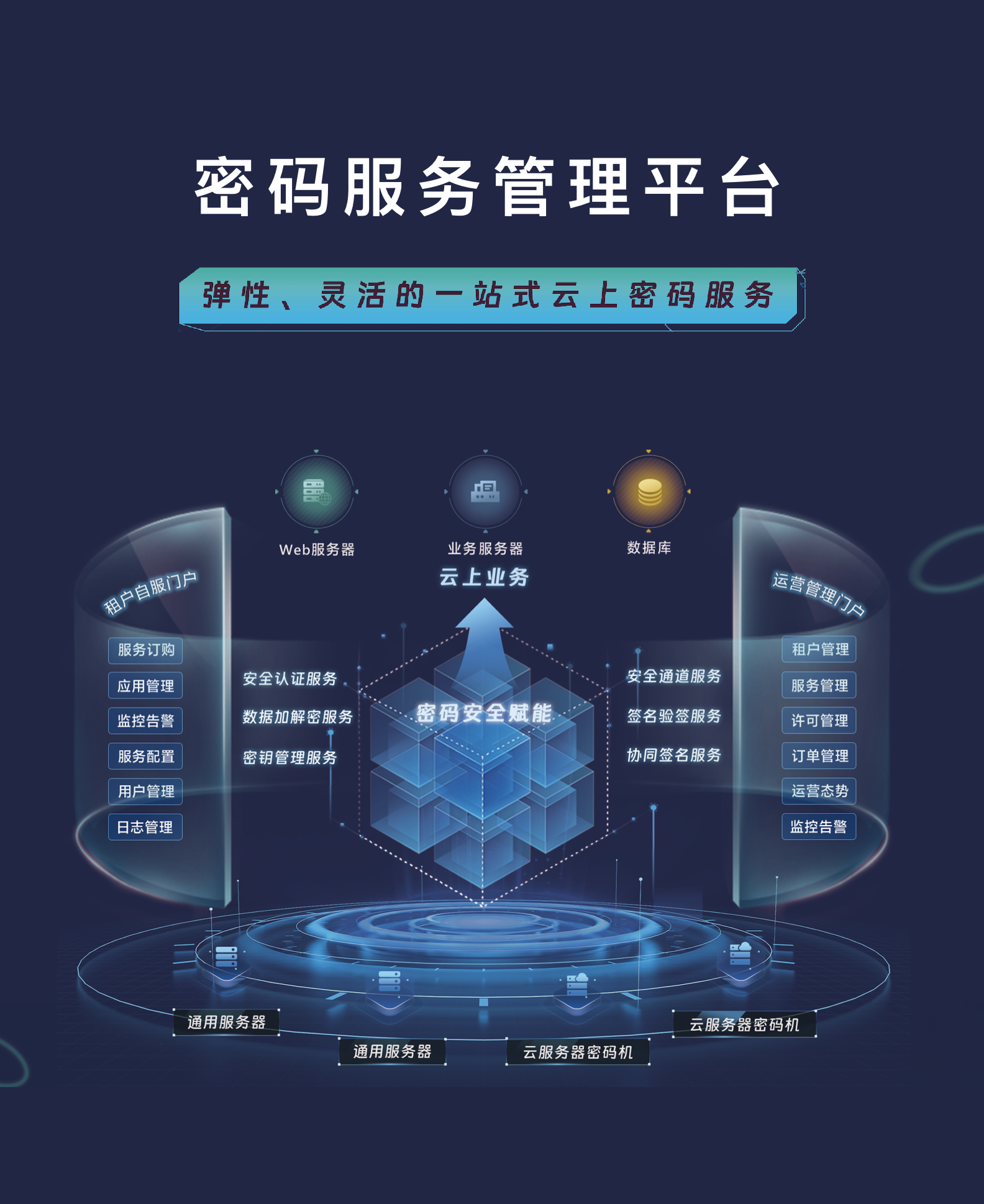



 安全托管服务
安全托管服务 运营管理服务
运营管理服务






媒体报道
一篇文章聊聊“欺骗技术”四大特性
国内对“欺骗技术”的应用,基本都容纳在一个产品里,一般简称“蜜罐”(当然蜜罐也有更明晰、确切的技术指向),往往其中包含了蜜罐、蜜饵、蜜标、蜜网、网络重定向、面包屑等等多种用于欺骗的技术组合。通常,我们理解这就是欺骗防御的实践应用。
“欺骗防御”后面增加“体系”两个字以后,要如何解释呢?还只是欺骗技术的排列组合么?编者认为不是!到底什么是欺骗防御体系,为什么这项技术会被认为是对抗APT组织攻击的有利手段?
在过去的安全防护体系当中,已经有了足够多的“孤岛”,所以这两年态势感知、SOAR、大数据智能分析技术大行其道。这时我们再增加一个“欺骗技术”的硬件盒子,起到欺骗作用也只是工具般的聊胜于无(这也是目前市场上对于这款产品的普遍认知,攻防演练时拿来用用,结束后束之高阁,归根结底不是客户有问题,而是产品定位有问题)。
欺骗防御体系到底如何建设?
编者认为,绝不是基于这项理论,将欺骗技术简简单单的排列组合。而是应该通过“欺骗技术”在现有防御体系当中的引用、结合,极大程度上催化防御能力,进而形成的高自动化、高联动体系。
这里我们不再解释技术本身,只说一说这项技术的四个特性:
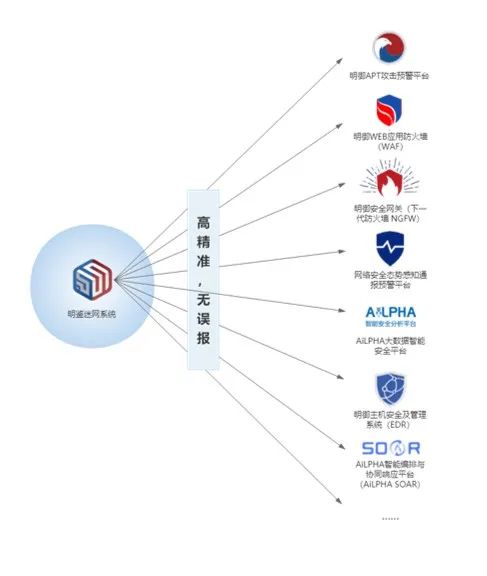
第一点:高精准,无误报
我们都知道,无论蜜罐还是蜜饵,或者散布的面包屑,都是针对攻击者定制的陷阱,其本身不是计算资源,放置的位置一般也不是内部员工、系统用户应该使用的位置,往往只有在攻击场景中才会被利用,所以欺骗技术的特性之一就是无误报。这对于态势感知、SOAR等需要实现自动处置的平台产品简直就是福音。
基于这个特性对于所有防御性产品的帮助具备同等效果,比如防火墙、终端防护产品的IP阻断。
第二点:“非规则”性分析
本质上来讲,欺骗产品其实并不需要“规则库”这种东西,更需要的是“高甜度”的仿真场景,我们只需要把攻击者踩进来执行的动作记录下来就足以说明、解决问题了。而这恰恰是过去APT攻击识别的难点“基于现有规则对攻击进行匹配,无法解决未知攻击的识别问题”。

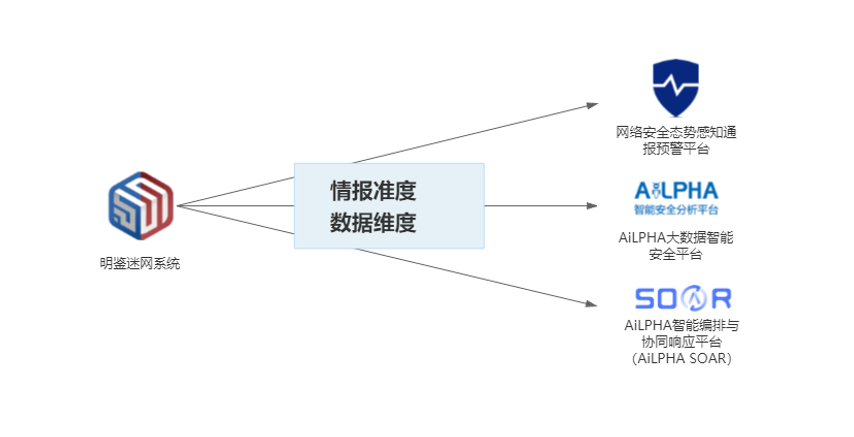
第三点:采集数据维度最全
欺骗技术通过仿真环境、数据的搭建诱导攻击者对其进行攻击、访问,而在这个过程当中,高交互的欺骗技术会给予攻击者一定的入侵入口,让其能够获得一定的操作权限,这时攻击者在其上的活动动作,将被监控手段进行采集。能够获取到的行为数据是非常全量的,包括原始流量PCAP包、Web访问记录、系统命令执行、数据库操作指令、攻击过程回放、落盘文件、端口扫描记录、暴力破解行为及认证凭证、蜜饵触动信息、攻击者指纹信息等10余种。运营人员可以通过这些数据更准确的还原其攻击行为,并判断攻击意图,为处置、防范提供决策上的帮助,这一点也是传统防御体系所不具备的能力。
在过去,建设态势感知、大数据平台,最大的几个工作难点在于:1、情报不够准确,依据不准确的数据进行分析、处置往往会极大浪费人力资源;2、数据维度不够丰富,往往要么早早阻断掉了,要么采集困难、资源消耗大,攻击意图就无法研判了。而现在欺骗技术的引用,这几个问题刚好都解决了。
最后一点,兜底
对于防御而言,始终没有万全的防御手段。防御的结果始终处于动态变化当中。一个全新的0day漏洞、攻击者通过社工手段找到的入侵跳板、防守方的一次疏漏,都可能导致原本完善的防御体系出现薄弱环节,致使防御失败。
在这时,欺骗防御中的欺骗技术蜜罐、蜜饵则可以发挥其作用:吸引攻击者,拖延时间。蜜罐往往仿真客户环境,建立仿真业务系统、PC机、数据库等,诱导攻击者对其实施攻击动作,而蜜饵则通过仿造具有高吸引力的数据内容,吸引攻击者获得。通过这种吸引攻击的作用,降低攻击者对真实目标进行入侵的概率,并拖延其攻击时间,给防守方提供更大的缓冲时间,为防御决战创造条件。
讲到这,大家是不是对欺骗技术的特性有一个大致的印象了。简而言之,欺骗技术对于现有的防护体系而言,可以是“联动的催化剂,决策的发动机”(本质上并不起到防御的作用,但是因为其技术特性,可以增强防御联动力,促进自动化决策的产生)。
具象到产品联动关系当中:
1
对整体防御起到兜底作用,当防御失效时,蜜罐起到迷惑作用、拖延攻击者
2
对大数据系统\SOAR等自动化分析处置凭条,提供低误报、高质量的监测数据,可作为事件处置决策的“自动化发起方”,并对黑客画像的绘制、行为的完整分析提供全面数据,作用不可替代
3
为IPS \ APT 等威胁检测系统,提供东西向流量,使威胁感知面增加至横纵联通
4
为防御型产品提供“阻断”依据
5
作为情报的采集器
那您的防御体系里是否缺少一个这样的“发动机”呢?
最后打个广告,安恒迷网欺骗防御系统,已实现上述所有功能。迷网,帮助您的安全运营更有效果。






