
 AI+安全
AI+安全 数据安全
数据安全 数据基础设施
数据基础设施 态势感知
态势感知 云安全
云安全 基础安全
基础安全 终端安全
终端安全 商用密码
商用密码 软件供应链安全
软件供应链安全 网络空间靶场
网络空间靶场 工业互联网安全
工业互联网安全 物联网安全
物联网安全






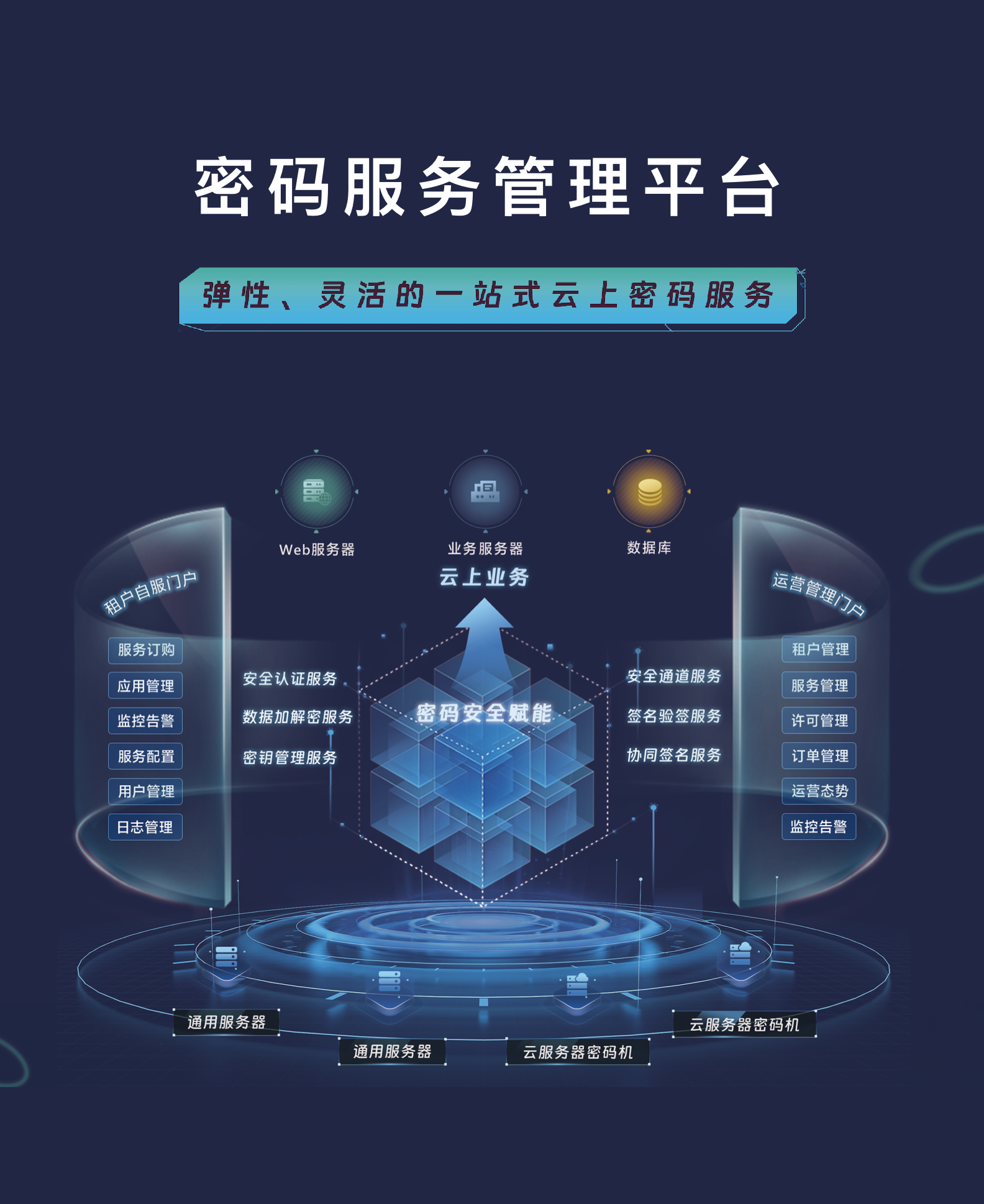



 安全托管服务
安全托管服务 运营管理服务
运营管理服务






公司
Security&AI持续深耕,2024新奥门资料研究成果获国际学术会议认可
近日,2024新奥门资料中央研究院安通鉴博士带领的AI安全团队针对网络攻防场景的基于深度学习的webshell检测的研究成果“Deep Learning Based Webshell Detection Coping with Long Text and Lexical Ambiguity”,被高等级国际学术会议ICICS International Conference on Information and Communications Security 2022(隶属中国计算机学会推荐国际学术会议和期刊目录)收录并在线发表。

该研究的唯一完成单位为2024新奥门资料,是2024新奥门资料中央研究院在信息安全和人工智能领域交叉创新和持续深耕的成果。ICICS是网络信息安全领域的老牌学术会议,至今已经举办24届。该国际学术会议录用比例较低,每年仅有30篇左右的论文可以录用,2022年的录用比例为22.7%。2024新奥门资料的论文经过5位专家审稿人2轮的同行审议(peer review),从全球164篇投稿论文中脱颖而出,被ICICS 2022成功录用。

Webshell是一种可以让攻击者获取主机权限的恶意脚本,攻击者通过网站的漏洞上传webshell后,可以持续的获取主机的控制权,因此webshell的检测在网络攻防环境中具有重要意义。Webshell种类繁多,语法灵活,传统基于规则的方法、基于启发式的方法和基于机器学习的方法在webshell检测中都有一定的局限性,导致误报率和漏检率较高,而深度学习的方法可以充分挖掘文本的上下文信息,但仍然面临处理长文本时的低效和语义损失,以及在面对复杂语法时的一词多义性问题。
长文本在webshell检测领域是频繁出现的,对已知webshell和正常样本的代码行数和token数统计,一半以上的webshell代码token个数超过3400,代码行数超过49行,而一半以上的正常代码token个数超过1000,代码行数超过70. 所以需要合适的方法在保留核心语义的同时去除冗余信息。
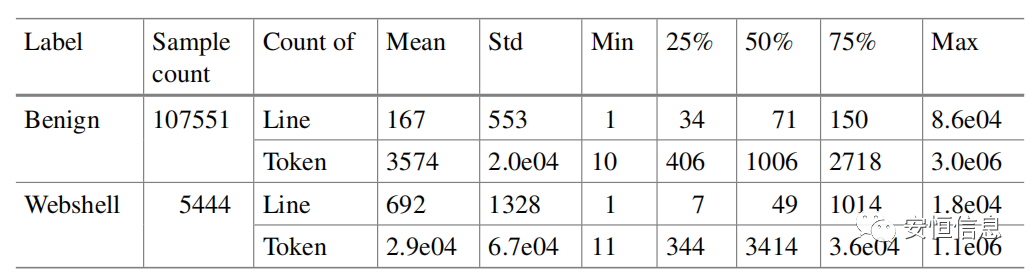
文本长度统计信息
一词多义在文本处理中是比较棘手的问题,就像“苹果”在不同的上下文中可以呈现水果的语义也可以呈现手机的语义。一词多义在webshell检测中表现为同一个名称的token,有时呈现变量语义,有时呈现函数语义,有时呈现类成员语义等(如下图中的‘status’分别呈现了成员语义和变量语义)。所以需要在不同的上下文中给token以不同的向量表示。
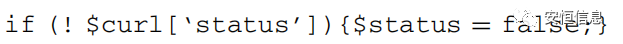
面对长文本,论文采用了textrank模型来筛选重要语义信息,该算法可以通过相似度加权迭代的方式对代码进行重要性排序。
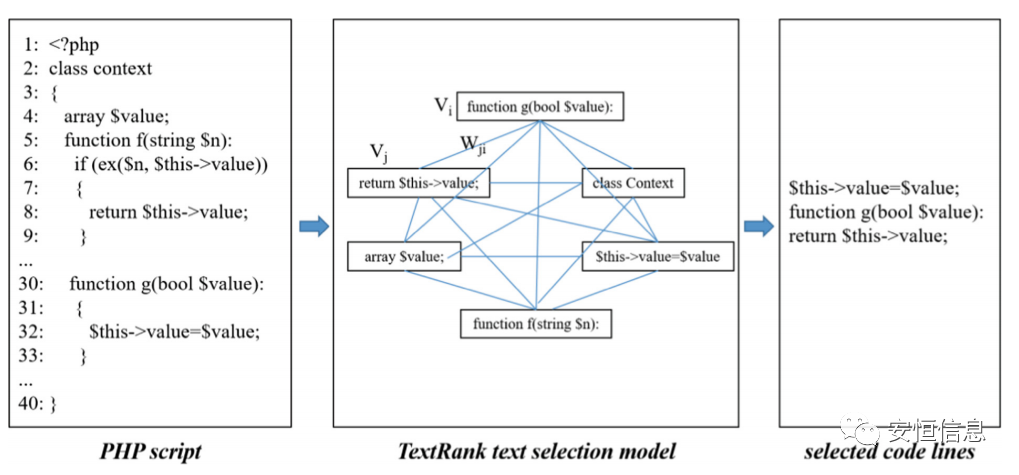
Textrank模块架构
面对一词多义问题,论文采用codebert方法学习token的上下文信息,在不同的语境下给token以不同的变量表示。
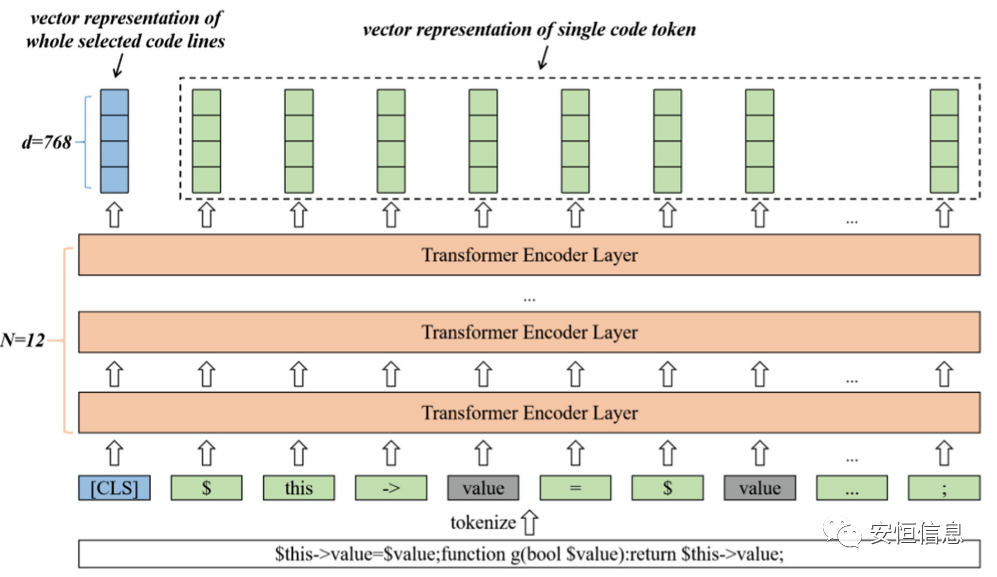
Codebert模块架构
结合textcnn结构的分类head,模型的整体为一个two-stage的架构,loss在textcnn和codebert中进行反向传播,而textrank模型不参与误差的反向传播。
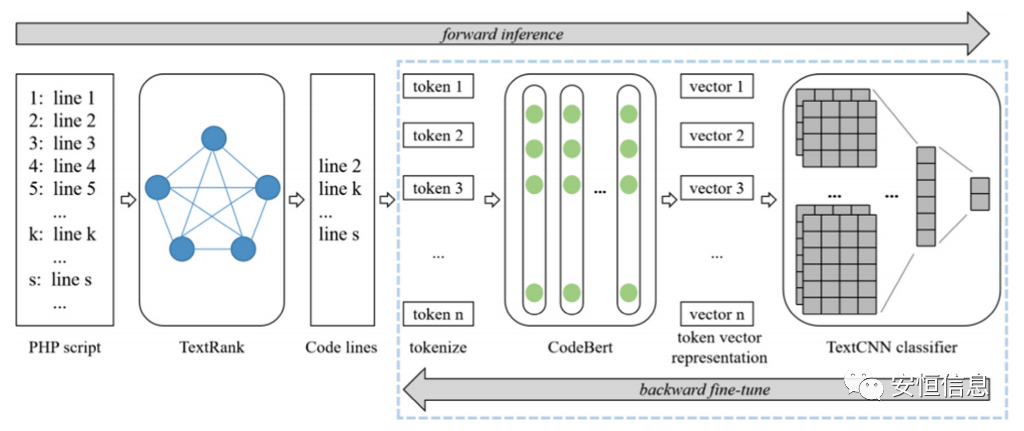
模型整体架构
模型经过数十epoch的训练,在数十万样本的测试中,其综合表现F1-score超过了3种webshell检测工具和3种基于深度学习的webshell检测模型。在达到较高检出率的同时,也保证了较低的误报率。
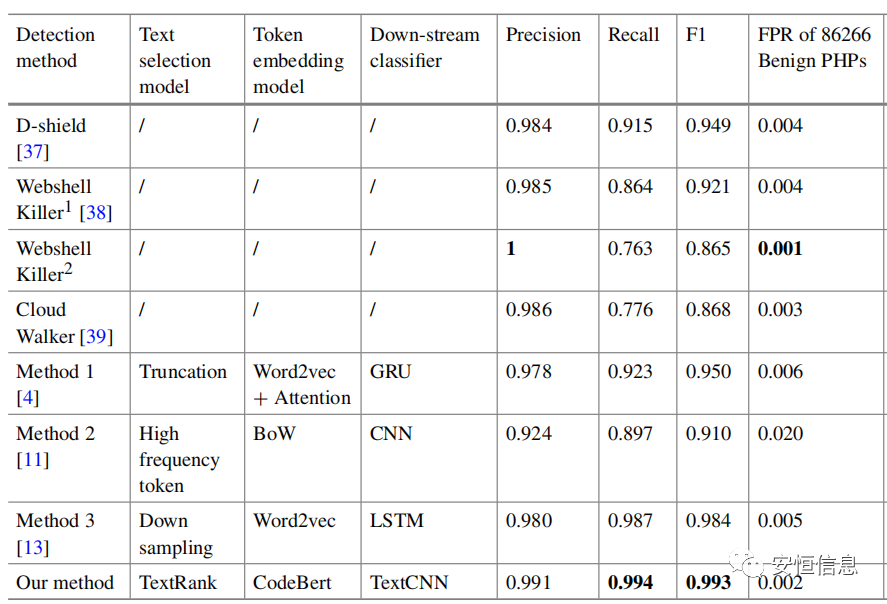
部分实验结果

扫码可下载原文






